La Non-Linéarité dans les Réseaux de Neurones Artificiels? Une Explication Intuitive
Si vous connaissez les réseaux de neurones artificiels, vous avez probablement entendu parler des fonctions d’activation et de l’importance de leur non-linéarité. Cependant, il est rare de trouver des explications claires sur ce que la non-linéarité signifie réellement et pourquoi elle est si vitale pour les réseaux neuronaux modernes. Cet article vise à clarifier ce concept simplement et à expliquer son impact sur les réseaux de neurones.
Non-linéarité : Géométrie vs. Topologie
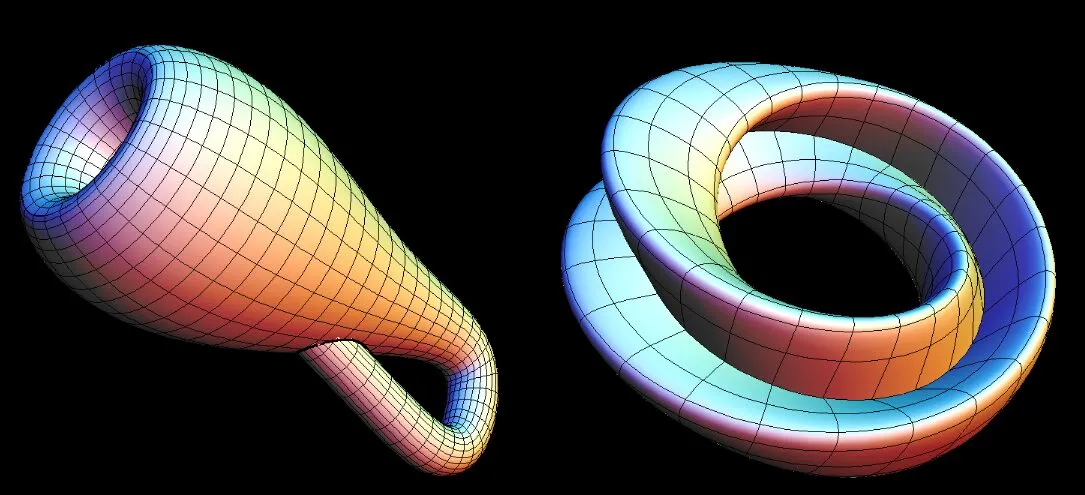
Pour comprendre la non-linéarité, nous devons d’abord comprendre la différence entre la géométrie et la topologie. La géométrie se concentre sur les propriétés locales des espaces. Par exemples, les distances et les angles; elle concerne donc les détails d’un espace. En revanche, la topologie concerne les propriétés globales. Par exemples, savoir si un cube est à l’intérieur d’une sphère, si quatre points se trouvent sur le même plan, ou si deux ensembles de points sont linéairement séparables.
Une transformation linéaire, telle que f(x)=ax+b, affecte la géométrie d’un espace en changeant les distances et les angles, mais n’altère pas la topologie. Par exemple, si nous déplaçons tout l’espace vers la droite, un cube à l’intérieur d’une sphère restera à l’intérieur parce que les deux bougent de manière égale. En essence, une transformation linéaire modifie uniformément l’espace.
À l’inverse, une opération non-linéaire pourrait laisser la sphère en place tout en déplaçant le cube à l’extérieur de celle-ci, appliquant des changements différents à différentes parties de l’espace. Cela altère fondamentalement les propriétés topologiques de l’espace, changeant la réponse à des questions comme « Le cube est-il à l’intérieur de la sphère ? ».
Fonctions d’activation non-linéaires
Un exemple d’opération non-linéaire est la fonction ReLU. ReLU reproduit l’entrée si elle est positive, sinon elle produit 0. Ainsi, elle traite différemment les parties positives et négatives de l’espace. Cette fonction est couramment utilisée dans les réseaux neuronaux en raison de ses propriétés avantageuses.
Un autre exemple est la fonction sigmoïde, qui se comporte de manière presque linéaire pour les valeurs proches de 0, mais qui borne les valeurs extrêmes entre 0 et 1. Ainsi, lorsqu’elle est appliquée à un espace entier, la fonction sigmoïde affecte différemment les différentes régions, ce qui la rend non-linéaire.
Non-linéarité en action
Voyons maintenant pourquoi la non-linéarité est cruciale dans les réseaux neuronaux. Grâce aux opérations non linéaires, nous pouvons couper, plier et tordre l’espace selon les besoins. De la même manière que nous pouvons déplacer le cube hors de la sphère dans l’exemple précédent, la non-linéarité dans les réseaux neuronaux nous permet de manipuler l’espace pour séparer des ensembles de points.
Un exemple simple utilisant ReLU
Considérons un réseau de neurones simple chargé de séparer deux ensembles de points (bleus et oranges) dans un espace 2D où un ensemble est à l’intérieur de l’autre. Nous ne pouvons pas séparer ces points de manière linéaire, nous allons donc utiliser un réseau ReLU à 2 couches. Passons par chaque couche étape par étape.
- Couche d’entrée : L’entrée se compose de deux variables X1 et X2 qui varient de -6 à 6.
- Première couche : Chaque neurone de cette couche applique ReLU pour définir des régions positives contenant uniquement des points oranges. Chaque neurone définit une région positive différente et ensemble, ils forment les frontières du centre de l’espace.
- Deuxième couche : Cette couche additionne ces régions, créant une région avec une valeur de 0 au centre et des valeurs positives autour. Parce que ReLU transforme les valeurs négatives en 0, la somme de ces régions reste 0. Cela définit donc une région au centre. Enfin, en ajoutant un biais négatif, cette couche définit deux régions : une positive et une négative, séparant efficacement les points.
- Couche de sortie : La couche finale inverse les valeurs pour classifier positivement les points bleus.
Illustration créée avec le neural playground
Comme nous pouvons le voir, ReLU est non-linéaire et affecte l’espace différemment dans différentes régions. Cette caractéristique nous permet de tracer des frontières et de définir des régions dans l’espace des données. Ce comportement non-linéaire se retrouve dans toutes les fonctions d’activation telles que la sigmoïde ou tanh.
A partir de cela, nous pouvons également comprendre pourquoi nous avons besoin de modèles plus grands pour des tâches complexes. L’espace représenté par les données liées à ces tâches complexes contient des régions plus complexes. Nous pouvons également comprendre l’impact du nombre de couches et du nombre de neurones par couche. Des couches plus larges nous permettent de définir plus de frontières et de régions, tandis que des couches multiples nous permettent de combiner plusieurs régions en des régions plus complexes. Ajouter des couches a un modèle permet de définir des regions exponentiellement plus complexes. Cela peut expliquer pourquoi nous préférons des réseaux plus profonds à des réseaux plus larges d’un point de vue topologique.
Conclusion
La non-linéarité, bien qu’étant un concept simple, est fondamentale pour les réseaux neuronaux. Comprendre les réseaux neuronaux comme une série de transformations topologiques a grandement amélioré ma compréhension de leur comportement. Bien que les exemples fournis soient basiques, les mêmes principes s’appliquent à des ensembles de données et des modèles plus complexes. Par exemple, un modèle comme GPT avec des centaines de couches effectue essentiellement de nombreuses découpes, pliages et torsions pour différencier les sujets des verbes, les noms propres des noms communs, et plus encore, afin de prédire le mot suivant dans une séquence.