GitHub Actions pour le CI/CD : Un Guide Complet
L'Intégration Continue et la Livraison Continue (CI/CD) sont au cœur de la philosophie DevOps. L'objectif est simple : au lieu de construire, pousser et déployer manuellement une application, nous définissons un pipeline qui effectue ces étapes automatiquement.
Les principaux avantages par rapport à un déploiement manuel en ligne de commande ou à un script de déploiement local sont :
- Répétabilité : les mêmes étapes de déploiement s'exécutent à chaque fois, réduisant les erreurs humaines.
- Suivi des versions : chaque déploiement est lié à un commit Git, ce qui facilite la connaissance des changements et de leur date. Si quelque chose casse, nous pouvons redéployer une image ou un commit précédent plus facilement.
- Automatisation : les déploiements peuvent se faire automatiquement après un push, une fusion ou une release.
- Meilleure sécurité : les processus CI/CD peuvent être isolés de votre environnement de production, permettant uniquement au runner de posséder les informations d'identification pour le déploiement.
- Auditabilité : les journaux CI/CD fournissent une trace claire de qui a déclenché un déploiement et des modifications apportées.
- Collaboration facilitée : tout le monde dans l'équipe suit le même processus de déploiement. Une fois le pipeline défini, l'ajout de nouvelles applications ou de nouveaux environnements devient plus facile.
Dans cet article, nous allons explorer en profondeur les GitHub Actions, ce qu'elles sont, comment elles fonctionnent et comment mettre en place un système CI/CD adéquat.
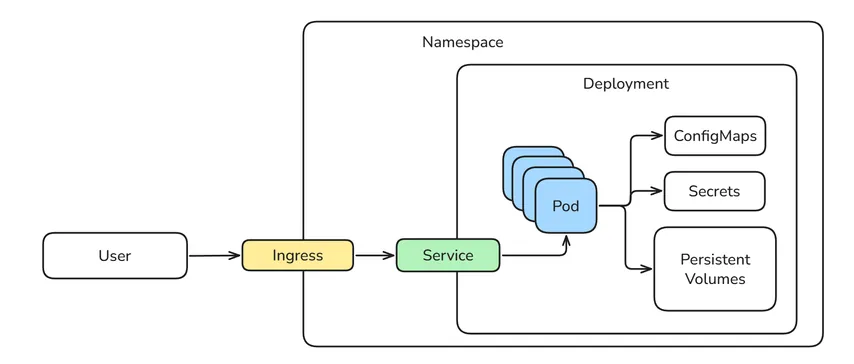
Anatomie d'un workflow
GitHub Actions est un système CI/CD intégré à GitHub. Il nous permet de définir des workflows automatisés qui se déclenchent lors d'événements sur le dépôt (par exemple, push, pull request, release).
Les workflows sont définis sous forme de fichiers YAML dans le répertoire .github/workflows/. Ils sont composés de jobs et de steps (étapes) :
- Jobs : Un groupe d'étapes qui s'exécutent sur le même conteneur.
- Steps : Des tâches individuelles (exécutant des commandes shell ou utilisant des actions préconstruites).
Nous nous concentrerons sur la création d'un workflow qui teste, construit et déploie notre application conteneurisée.
Un workflow CI/CD de base suit généralement cette structure :
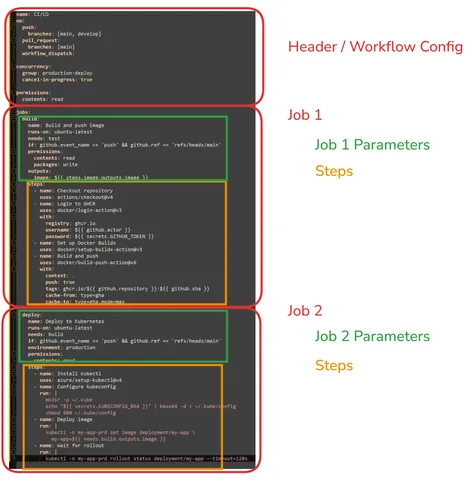
En-tête / Configuration du workflow
D'abord, nous avons le haut du workflow où nous définissons un ensemble de paramètres globaux. Un en-tête de base ressemblerait à ceci :
name: Build and Deploy to Kubernetes
on:
push:
branches:
- main
- develop
workflow_dispatch:Le champ name définit le nom d'affichage du workflow dans l'interface utilisateur de GitHub Actions. C'est utile car un dépôt peut avoir plusieurs workflows.
La section on définit quand le workflow doit s'exécuter. Les workflows GitHub Actions sont déclenchés par des événements tels que push, pull_request, schedules, releases, ou une exécution manuelle. Il s'applique dès que le fichier de workflow est présent dans le dépôt Git sur GitHub.
Dans cet exemple, le workflow s'exécute dans deux situations :
- lorsque du code est poussé vers les branches
mainoudevelop - lorsque nous démarrons manuellement le workflow depuis l'interface GitHub Actions en utilisant
workflow_dispatch. GitHub requiert ce déclencheur pour afficher le bouton "Run workflow" dans l'onglet Actions.
L'option workflow_dispatch vous permet également de définir des entrées si vous souhaitez contrôler plus précisément l'exécution manuelle. Par exemple, ici, nous définissons une variable environment :
on:
workflow_dispatch:
inputs:
environment:
description: "Environment to deploy to"
required: true
default: "staging"
type: choice
options:
- staging
- productionDe nombreux autres déclencheurs existent, tels que :
pull_request: S'exécute lorsqu'une pull request a une activité quelconque (création, mise à jour, ...).pull_request_target: Similaire àpull_request, il exécute un workflow dans le contexte du dépôt de base, lui permettant de gérer des PR avec des permissions plus élevées (plus risqué mais parfois utile).
Pour push, pull_request, et pull_request_target, vous pouvez spécifier des sous-paramètres pour affiner le moment où le workflow s'exécute :
branches/branches-ignore: Filtre par noms de branches (supporte les jokers).tags/tags-ignore: Filtre par tags Git (supporte les jokers).paths/paths-ignore: S'exécute uniquement si au moins un fichier modifié correspond au modèle.
on:
push:
branches:
- main
- "releases/**"
tags:
- "v*"
paths:
- "src/**"
- "Dockerfile"Vous pouvez déclencher des workflows en fonction de presque tous les événements qui se produisent sur GitHub. Beaucoup de ces événements acceptent un paramètre types pour spécifier quels types d'activité déclenchent l'exécution (par exemple, created, edited, deleted). Voici les événements les plus courants :
| Paramètre | Description du déclencheur |
|---|---|
| workflow_call | Rend le workflow réutilisable pour qu'il puisse être appelé par d'autres workflows. |
| workflow_run | Déclenché lorsqu'un autre workflow est demandé ou terminé. |
| schedule | Exécute périodiquement le workflow à des moments précis en utilisant la syntaxe cron POSIX. |
| repository_dispatch | Déclenché par une requête HTTP à l'API GitHub depuis un système externe. |
| issues | Déclenché lorsqu'une issue est ouverte, modifiée, fermée, etc. |
| issue_comment | Déclenché lorsqu'un commentaire est créé, modifié ou supprimé sur une issue ou une PR. |
| release | Déclenché lorsqu'une release est créée, publiée ou modifiée. |
| create | Déclenché lorsqu'une branche ou un tag est créé. |
| delete | Déclenché lorsqu'une branche ou un tag est supprimé. |
| discussion | Déclenché lorsqu'une Discussion GitHub est créée ou modifiée. |
| discussion_comment | Déclenché lorsqu'un commentaire sur une discussion est créé ou modifié. |
| fork | Déclenché lorsque quelqu'un forke le dépôt. |
| gollum | Déclenché lorsqu'une page wiki est créée ou mise à jour. |
| label | Déclenché lorsqu'une étiquette est créée, modifiée ou supprimée. |
| milestone | Déclenché lorsqu'un jalon est créé, ouvert, terminé ou modifié. |
| project | Déclenché lorsqu'un tableau de projet classique est modifié. |
| registry_package | Déclenché lorsqu'un paquet est publié ou mis à jour (par exemple, GHCR). |
| status | Déclenché lorsque le statut d'un commit Git change. |
| watch | Déclenché lorsqu'un dépôt est mis en favori (starred). |
Vous pouvez combiner n'importe lequel de ces paramètres dans un seul workflow. Le workflow s'exécutera si l'un des événements définis se produit.
on:
push:
branches: [main]
schedule:
- cron: "0 12 * * *"
issues:
types: [opened, edited]
workflow_dispatch:jobs
Un workflow contient un ou plusieurs jobs. Un job est un groupe d'étapes qui s'exécutent sur le même runner. Dans les workflows simples, nous commençons souvent avec un seul job. Voici un job de base :
jobs:
build-and-deploy:
name: Build and deploy
runs-on: ubuntu-latest
env:
IMAGE_NAME: my-appIci, build-and-deploy est l'identifiant interne du job. name est le nom lisible par l'homme affiché dans l'interface de GitHub. Enfin, le champ runs-on définit sur quelle machine le job s'exécutera. Actuellement, le runner est défini sur ubuntu-latest, ce qui signifie que le job s'exécute sur un runner Linux hébergé par GitHub.
La section env définit des variables d'environnement qui peuvent être réutilisées à l'intérieur du job.
Un job GitHub Actions peut être configuré avec plusieurs paramètres optionnels qui contrôlent où il s'exécute, combien de temps il peut s'exécuter, quelles permissions il a, et comment il se comporte en cas d'échec.
Par exemple, un job peut s'exécuter à l'intérieur d'une image de conteneur spécifique :
jobs:
build:
runs-on: ubuntu-latest
container:
image: node:20-alpinePar défaut, un job s'exécute directement sur le runner hébergé par GitHub, comme ubuntu-latest. Cependant, l'utilisation de container vous permet d'exécuter le job à l'intérieur d'une image Docker prédéfinie.
C'est utile lorsque votre workflow a besoin d'outils ou de dépendances spécifiques. Vous pourriez installer ces outils pendant le workflow, mais cela ralentit chaque exécution. Une meilleure option est souvent d'utiliser une image personnalisée où les outils requis sont déjà installés.
Un job peut également définir de nombreux autres paramètres :
jobs:
build:
runs-on: ubuntu-latest
# Exécute ce job uniquement sur la branche main
if: github.ref == 'refs/heads/main'
# Arrête le job s'il dure plus de 15 minutes
timeout-minutes: 15
# N'échoue pas tout le workflow si ce job échoue
continue-on-error: true
# Limite ce que le job est autorisé à faire
permissions:
contents: read # Lire depuis le dépôt
packages: write # Publier des paquets
# Attache ce job à un environnement GitHub
environment: production
# Exécute le même job avec plusieurs valeurs
strategy:
matrix:
node-version: [18, 20, 22]
fail-fast: true
max-parallel: 2
# Démarre des conteneurs supplémentaires nécessaires pendant le job, comme des bases de données ou des caches
services:
postgres:
image: postgres:15
ports:
- 5432:5432
steps:
- uses: actions/checkout@v4
- name: Use Node.js
run: echo "Running with Node ${{ matrix.node-version }}"Les jobs peuvent également produire des sorties (outputs) que d'autres jobs peuvent réutiliser :
jobs:
build:
runs-on: ubuntu-latest
outputs:
version: ${{ steps.get_version.outputs.version }}
steps:
- id: get_version
run: echo "version=1.0.0" >> "$GITHUB_OUTPUT"$GITHUB_OUTPUT est un chemin de fichier temporaire fourni par GitHub Actions où une étape peut écrire des valeurs de sortie que les étapes ou jobs ultérieurs peuvent réutiliser. Cela permet à un autre job d'accéder à la valeur :
jobs:
deploy:
needs: build
runs-on: ubuntu-latest
steps:
- run: echo "Deploying version ${{ needs.build.outputs.version }}"Vous pouvez également définir des paramètres par défaut pour toutes les étapes run à l'intérieur d'un job :
jobs:
build:
runs-on: ubuntu-latest
defaults:
run:
shell: bash
working-directory: ./frontendEnfin, concurrency est utile lorsqu'une seule version d'un job doit s'exécuter à la fois, en particulier pour les déploiements :
jobs:
deploy:
runs-on: ubuntu-latest
concurrency:
group: production-deploy
cancel-in-progress: trueAvec cancel-in-progress: true, si une nouvelle instance du workflow est déclenchée alors qu'une autre est encore en cours, GitHub annule l'ancienne et ne conserve que le déploiement le plus récent.
steps
Un job est composé d'une ou plusieurs étapes (steps).
Chaque étape représente une tâche unique dans le job. Une étape peut soit :
- Exécuter une commande shell en utilisant
run. - Utiliser une GitHub Action préconstruite en utilisant
uses.
Par exemple :
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v4
- name: Install dependencies & Test
run: |
npm install
npm testDans cet exemple, la première étape utilise une action existante, tandis que l'autre étape exécute des commandes shell. Spécifiquement, la première étape utilise l'action officielle checkout pour télécharger le code du dépôt dans le runner ; en gros, cela exécute un git clone. Il existe de nombreuses actions prédéfinies comme github/super-linter@v7 pour la vérification du code. Mais vous pouvez aussi créer votre propre action personnalisée à partager entre les workflows et les projets.
Note : le symbole | dans la commande run nous permet d'écrire plusieurs commandes shell en une seule étape.
Une étape peut également définir plusieurs paramètres optionnels similaires à ceux des jobs :
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Install dependencies
if: github.ref == 'refs/heads/main'
timeout-minutes: 10
continue-on-error: true
working-directory: ./frontend
shell: bash
env:
NODE_ENV: production
run: npm installCertaines actions acceptent également des paramètres d'entrée en utilisant with :
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: 20
cache: npmIci, nous utilisons setup-node qui configure la version demandée de Node.js sur le runner et l'ajoute au PATH, afin que les commandes comme node, npm, et npx fonctionnent dans les étapes ultérieures. Le paramètre with passe des valeurs de configuration à l'action. Dans ce cas, il indique à setup-node quelle version de Node.js installer et active la mise en cache de npm.
Les étapes peuvent aussi avoir un id. C'est utile lorsqu'une autre étape doit réutiliser sa sortie :
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Get version
id: get_version
run: echo "version=1.0.0" >> "$GITHUB_OUTPUT"
- name: Print version
run: echo "Version is ${{ steps.get_version.outputs.version }}"La première étape écrit une valeur dans $GITHUB_OUTPUT. Comme l'étape a un id, les étapes ultérieures peuvent accéder à cette valeur en utilisant {{ steps.get_version.outputs.version }}.
En bref : Les jobs définissent l'environnement et les règles d'exécution. Les étapes définissent le travail réel à effectuer.
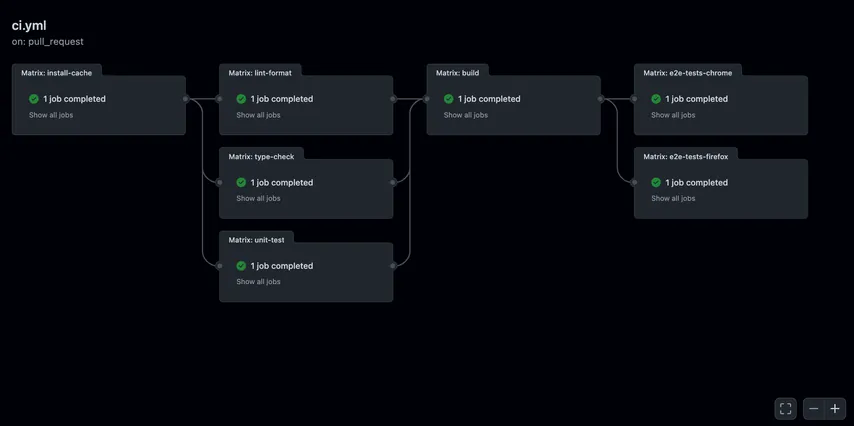
Création du Workflow
Maintenant que nous comprenons l'anatomie d'un workflow, assemblons un pipeline CI/CD complet. Cet exemple de workflow automatisera trois étapes critiques : tester votre code, construire une image de conteneur et la déployer sur votre cluster Kubernetes.
Le Workflow Complet
Créez un dépôt de test et enregistrez le YAML ci-dessous dans .github/workflows/deploy.yml à la racine de votre dépôt. Ensuite, commitez et poussez ce fichier.
name: CI/CD
on:
push:
branches: [main, develop]
pull_request:
branches: [main]
workflow_dispatch:
concurrency:
group: production-deploy
cancel-in-progress: true
permissions:
contents: read
jobs:
test:
name: Tester l'application
runs-on: ubuntu-latest
steps:
- name: Récupérer le dépôt
uses: actions/checkout@v4
- name: Configurer Node.js
uses: actions/setup-node@v4
with:
node-version: 20
cache: npm
- name: Installer les dépendances
run: npm ci
- name: Lancer les tests
run: npm test
build:
name: Créer et pousser l'image
runs-on: ubuntu-latest
needs: test
if: github.event_name == 'push' && github.ref == 'refs/heads/main'
permissions:
contents: read
packages: write
outputs:
image: ${{ steps.image.outputs.image }}
steps:
- name: Récupérer le dépôt
uses: actions/checkout@v4
- name: Définir le nom de l'image
id: image
run: |
IMAGE="ghcr.io/${{ github.repository }}:${{ github.sha }}"
echo "image=$IMAGE" >> "$GITHUB_OUTPUT"
- name: Connexion à GHCR
uses: docker/login-action@v3
with:
registry: ghcr.io
username: ${{ github.actor }}
password: ${{ secrets.GITHUB_TOKEN }}
- name: Configurer Docker Buildx
uses: docker/setup-buildx-action@v3
- name: Créer et pousser
uses: docker/build-push-action@v6
with:
context: .
push: true
tags: ${{ steps.image.outputs.image }}
cache-from: type=gha
cache-to: type=gha,mode=max
deploy:
name: Déployer sur Kubernetes
runs-on: ubuntu-latest
needs: build
if: github.event_name == 'push' && github.ref == 'refs/heads/main'
environment: production
permissions:
contents: read
steps:
- name: Installer kubectl
uses: azure/setup-kubectl@v4
- name: Configurer kubeconfig
run: |
mkdir -p ~/.kube
echo "${{ secrets.KUBECONFIG_B64 }}" | base64 -d > ~/.kube/config
chmod 600 ~/.kube/config
- name: Déployer l'image
run: |
kubectl -n my-app-prd set image deployment/my-app \
my-app=${{ needs.build.outputs.image }}
- name: Attendre le déploiement
run: |
kubectl -n my-app-prd rollout status deployment/my-app --timeout=120sSécurité : Stocker un kubeconfig sous forme de secret CI encodé en Base64 est risqué. Le Base64 n’est pas un mécanisme de chiffrement, et ce fichier fournit souvent un accès privilégié et de longue durée au cluster. Privilégiez des alternatives plus sûres, comme un runner auto-hébergé avec des permissions Kubernetes limitées, ou une approche GitOps où le cluster récupère lui-même les changements, plutôt que d’exposer des identifiants d’accès au cluster à votre pipeline CI.
Exécution et Vérification
- Déclenchement : Le workflow est configuré pour s'exécuter à chaque
pushetpull_requestsur la branchemainoupushsur la branchedevelop. Il peut également être déclenché manuellement grâce au déclencheurworkflow_dispatch. - Suivi : Accédez à l'onglet Actions de votre dépôt GitHub. Vous y verrez le workflow
CI/CD. Cliquez sur la dernière exécution pour observer les jobs de Test, Build et Deploy en temps réel.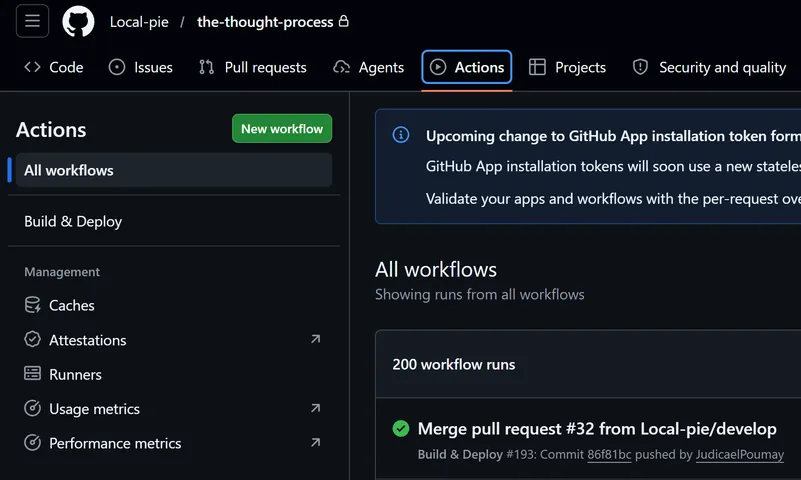
Cet exemple de workflow est composé de trois jobs :
- Job de Test : Assure la stabilité du code. Nous utilisons
npm cipour une installation fiable des dépendances. - Job de Build : Ne s'exécute que sur les
pushversmainpour éviter les constructions d'images inutiles. Nous taguons l'image avec le SHA du commit spécifique (${{ github.sha }}) pour assurer une traçabilité exacte. - Job de Déploiement : Met à jour le cluster Kubernetes. La commande
rollout statusagit comme une étape de vérification automatisée pour confirmer que le nouveau déploiement est réussi.
Bien sûr, sans projet attaché, cela ne fera pas grand-chose. Si vous voulez voir un vrai dépôt avec un workflow simple, voici un exemple d'un petit projet sur lequel je travaille : https://github.com/Local-pie/PiTTS/blob/main/.github/workflows/deploy.yml. C'est un workflow très basique et non optimisé qui construit et pousse un frontend et un backend.
GitHub Actions Avancées
Maintenant que nous avons une compréhension approfondie de la syntaxe du workflow et de ses principales fonctionnalités, passons à un territoire plus avancé.
Variables Intégrées
GitHub Actions fournit des valeurs intégrées via des contextes. GitHub fournit des contextes tels que github, env, vars, secrets, steps, et runner pour accéder dynamiquement aux informations du workflow. L'un des contextes les plus utiles est le contexte github, qui contient des informations sur l'exécution du workflow, le dépôt, la branche, le commit, l'acteur et l'événement qui a déclenché le workflow. GitHub expose également beaucoup de ces valeurs comme variables d'environnement par défaut telles que GITHUB_SHA, GITHUB_REF, et GITHUB_RUN_ID.
Les valeurs utiles incluent :
| Variable | Signification | Cas d'utilisation |
|---|---|---|
${{ github.sha }} | SHA du commit qui a déclenché le workflow | Taguer les images Docker |
${{ github.ref }} | Référence Git complète | Vérifier si le workflow s'exécute sur main |
${{ github.ref_name }} | Nom court de la branche ou du tag | Créer des tags d'image basés sur la branche |
${{ github.repository }} | Nom du dépôt avec le propriétaire | Construire les noms d'image |
${{ github.repository_owner }} | Propriétaire ou organisation du dépôt | Construire les chemins de registre |
${{ github.actor }} | Utilisateur qui a déclenché le workflow | Messages de journalisation ou d'audit |
${{ github.event_name }} | Événement qui a déclenché le workflow | Exécuter une logique différente pour push ou pull_request |
${{ github.run_id }} | ID unique de l'exécution du workflow | Créer des ID de déploiement traçables |
${{ github.run_number }} | Numéro d'exécution incrémentiel pour le workflow | Créer des numéros de build lisibles |
${{ github.workflow }} | Nom du workflow | Logs, notifications, métadonnées de déploiement |
${{ github.job }} | ID du job actuel | Débogage ou journalisation |
${{ github.workspace }} | Chemin où le dépôt est cloné | Chemins de fichiers dans les scripts |
Pour les tags d'images Docker, ceux-ci sont particulièrement utiles :
${{ github.sha }} ${{ github.ref_name }} ${{ github.run_number }}Une stratégie courante consiste à pousser plusieurs tags pour la même image :
docker build \
-t ghcr.io/my-org/my-app:${{ github.sha }} \
-t ghcr.io/my-org/my-app:${{ github.ref_name }} \
-t ghcr.io/my-org/my-app:latestDésormais, chaque build a un tag d'image unique. Au lieu de simplement pousser latest, nous savons exactement quel commit a produit chaque image. Cela vous donne différents niveaux de traçabilité :
| Tag | Utilité |
|---|---|
${{ github.sha }} | Commit exact, idéal pour la reproductibilité |
${{ github.ref_name }} | Nom de la branche ou du tag, utile pour main, dev, ou v1.0.0 |
latest | Pratique par défaut, mais pas précis |
build-${{ github.run_number }} | Identifiant de build lisible par l'homme |
Secrets Et Variables
Vous ne voudriez pas stocker votre clé API ou d'autres informations d'identification sur votre dépôt en texte clair. Ce serait imprudent. Les Secrets GitHub vous permettent de stocker ce genre de secrets et d'y accéder ensuite dans un workflow en utilisant le contexte secrets. Par exemple :
${{ secrets.REGISTRY_PASSWORD }}
Dans cet exemple, nous utilisons des secrets pour nous connecter à un registre de conteneurs :
- name: Login to GHCR
uses: docker/login-action@v3
with:
registry: ghcr.io
username: ${{ github.actor }}
password: ${{ secrets.GITHUB_TOKEN }}
Pour créer un secret, allez dans les paramètres de votre dépôt sous Secrets and Variables. Ici, vous pouvez créer des secrets par environnement, au niveau du dépôt ou même au niveau de l'organisation si vous en faites partie.
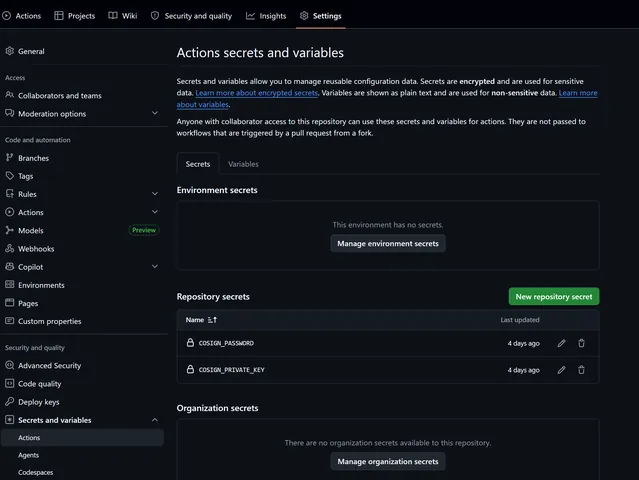
Si un secret a le même nom dans les sections organisation, dépôt et environnement, GitHub utilisera le plus spécifique, donc : Environnement > Dépôt > Organisation.
D'ailleurs, si vous vous interrogez sur les environnements, c'est ce que fait le paramètre environment du job : il définit quel environnement utiliser et donc quels secrets et variables nous utilisons.
De même, vous pouvez aussi créer des variables qui sont un peu comme des secrets, sauf qu'une fois que vous écrivez un secret, vous ne pouvez plus jamais voir sa valeur depuis l'interface. Pour les variables, vous pouvez les lire plus tard.
Jobs Multiples
Un workflow peut également être divisé en plusieurs jobs. Par exemple :
name: CI/CD pipeline
on:
push:
branches:
- main
jobs:
test:
name: Run tests
runs-on: ubuntu-latest
steps:
- name: Checkout source code
uses: actions/checkout@v4
- name: Run tests
run: |
echo "Running tests..."
deploy:
name: Deploy application
runs-on: ubuntu-latest
needs: test
steps:
- name: Deploy
run: |
echo "Deploying application..."Ici, nous avons deux jobs :
test: vérifie que l'application fonctionnedeploy: déploie l'application
La partie importante est :
needs: testLes jobs s'exécutent en parallèle par défaut, ce qui peut être utile, mais parfois nous avons besoin qu'ils soient séquentiels. needs: test signifie que le job deploy ne démarre qu'après que le job test soit terminé et ait réussi. C'est utile car nous ne voulons généralement pas déployer une application si les tests échouent.
Grâce à cela, nous pouvons construire des pipelines complexes avec des dépendances et des jobs parallèles. Par exemple, exécuter plusieurs tests en parallèle avant de construire et de déployer.
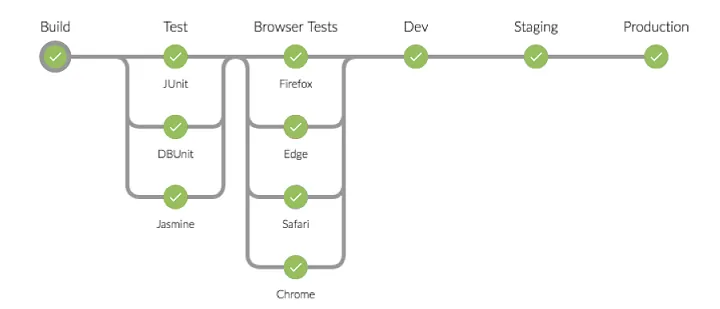
Les jobs doivent être divisés lorsque nous voulons séparer les responsabilités. Par exemple, les tests, la construction et le déploiement peuvent être trois jobs différents. Cela rend le pipeline plus facile à lire, permet à certains jobs de s'exécuter en parallèle et nous permet de donner des permissions différentes à différentes parties du pipeline.
permissions
Un workflow peut également définir des permissions pour le GITHUB_TOKEN par défaut. C'est important car nous ne devrions donner au workflow que les permissions dont il a réellement besoin. GitHub recommande de configurer les permissions du token plutôt que de donner aux workflows un accès inutile.
Par exemple :
permissions:
contents: read
packages: writeCela signifie que le workflow peut lire le contenu du dépôt et écrire des paquets, mais il ne reçoit pas automatiquement toutes les permissions possibles. D'autres permissions existent pour créer automatiquement des Pull Requests, commenter des issues, et plus encore !
Concurrency
Imaginez que vous poussez le commit A, puis rapidement le commit B. Sans contrôle de la concurrence, les deux déploiements pourraient s'exécuter en parallèle. Selon le timing, le commit A pourrait se terminer après le commit B et revenir accidentellement à une version antérieure de l'application.
Le paramètre concurrency résout ce problème :
concurrency:
group: production-deploy
cancel-in-progress: trueUn groupe de concurrence garantit qu'un seul workflow ou job du même groupe s'exécute à la fois. Avec cancel-in-progress: true, tout déploiement en cours est annulé lorsqu'un nouveau est déclenché, de sorte que seul le déploiement le plus récent continue. Avec cancel-in-progress: false, le déploiement en cours est autorisé à se terminer avant que le suivant ne commence.
Conseils de pro
Une meilleure étape de déploiement final
Après avoir déployé une application sur Kubernetes, ce que vous ferez très probablement, vous pouvez ajouter ceci :
- name: Wait for rollout
run: |
kubectl -n my-app-prd rollout status deployment/my-app --timeout=180s
- name: Show running image
run: |
kubectl -n my-app-prd get deployment my-app \
-o=jsonpath='{.spec.template.spec.containers[0].image}'
echo
- name: Smoke test
run: |
curl --fail --silent --show-error https://example.com/healthCela vous donne trois niveaux de confiance :
- Kubernetes a accepté le déploiement.
- Les nouveaux pods sont devenus prêts (
ready). - Le point d'accès public de l'application répond.
C'est bien mieux que de simplement appliquer du YAML.
Éviter le piège du latest
De nombreux tutoriels utilisent :
ghcr.io/owner/app:latest
C'est simple, mais cela crée une ambiguïté. Si le pod exécute latest, quel commit est réellement déployé ? Pire, Kubernetes peut ne pas toujours tirer l'image quand vous vous y attendez, en fonction du tag et de imagePullPolicy.
Pour les pipelines de déploiement, préférez des tags immuables ou traçables :
ghcr.io/owner/app:<commit-sha>
Optionnellement, publiez plusieurs tags :
ghcr.io/owner/app:<commit-sha>
ghcr.io/owner/app:main
ghcr.io/owner/app:v1.2.3
Mais déployez en utilisant le SHA du commit.
GitOps : CI/CD basé sur le Pull
Le workflow ci-dessus utilise un déploiement basé sur le push : GitHub Actions exécute le workflow et met à jour le déploiement.
Une autre approche est le GitOps. Avec GitOps, le cluster tire l'état désiré de Git en utilisant des outils comme Argo CD ou Flux. Dans ce modèle, GitHub Actions pourrait uniquement construire l'image et mettre à jour un dépôt de manifestes. Le cluster remarque le changement et l'applique.
Le GitOps est préférable lorsque vous ne voulez pas que GitHub Actions détienne des informations d'identification directes du cluster.
Utiliser les Environnements GitHub
Comme je l'ai expliqué dans la section Secrets et Variables, vous pouvez définir l'environnement dans lequel un job s'exécute avec :
jobs:
build:
runs-on: ubuntu-latest
# Environnement à utiliser
environment: ${{ github.ref_name == 'main' && 'production' || 'staging' }}
steps:
- uses: actions/checkout@v4
- name: Use Node.js
run: echo "Running with Node ${{ matrix.node-version }}"Notez la condition ternaire utilisée. Pour la branche main, nous utilisons l'environnement de production, sinon nous utilisons staging.
C'est utile dans les situations où différents environnements ont des besoins différents. Par exemple, vous avez un secret de base de données qui change en fonction de l'environnement.
Avoir des environnements séparés est une bonne habitude même pour un petit projet. Un blog personnel n'a peut-être pas besoin d'un processus de release d'entreprise complet, mais il bénéficie toujours d'une frontière claire entre les tests et la production.
Une configuration courante est :
Pull request -> test uniquement
Push vers develop -> build et déploiement en préproduction
Pull request vers main -> approbation manuelle -> déploiement en production
Prochaines étapes
Une fois que ce pipeline de base fonctionne, vous pouvez l'améliorer progressivement :
- Ajouter des environnements de
staginget de production. - Ajouter une approbation manuelle avant la production.
- Utiliser Helm ou Kustomize au lieu de
kubectldirect. - Ajouter une analyse des vulnérabilités.
- Signer les images.
- Déployer par
digestau lieu detag. - Ajouter des environnements de prévisualisation pour les pull requests.
- Créer des workflows réutilisables si plusieurs dépôts partagent le même pipeline.
- Ajouter des notifications en cas d'échec de déploiement.
N'essayez pas d'ajouter tout cela le premier jour. Un bon pipeline CI/CD doit évoluer comme n'importe quel autre projet. Commencez par les tests, la construction d'images, le déploiement et la vérification du déploiement. Améliorez ensuite la sécurité et l'observabilité étape par étape.
Erreurs courantes dans les workflows de déploiement GitHub Actions
Erreur 1 : Déployer depuis des pull requests
Les pull requests peuvent contenir du code non fiable. Soyez prudent avec les secrets et les déploiements dans les workflows de pull request. Utilisez les pull requests pour les tests. Utilisez les mises à jour de branches pour le déploiement.
Erreur 2 : Oublier les secrets de tirage d'image (image pull secrets)
Si les images GHCR sont privées, Kubernetes a aussi besoin d'identifiants. Le fait que le workflow puisse pousser l'image ne signifie pas que le cluster peut la tirer.
Erreur 3 : Installer des outils manuellement dans chaque workflow
Si votre job de déploiement a besoin de kubectl, helm, kustomize, yq et des CLI cloud, envisagez de créer une petite image CI personnalisée ou d'utiliser une action de configuration bien maintenue. Cela garde les workflows plus rapides et plus propres.
Erreur 4 : Déployer en utilisant latest
Bien que plus simple, l'utilisation de l'image latest rend plus difficile le débogage et la traçabilité de l'origine d'une image. Cela peut également conduire à des situations où Kubernetes tire la mauvaise image en production si vous poussez latest en pré-production.
Dépannage
En attente qu'un runner prenne en charge ce job
Le job est en file d'attente mais aucun runner correspondant n'est disponible.
Vérifiez :
- Est-ce que
runs-onest correct ? - Si vous hébergez vous-même, le runner auto-hébergé est-il en ligne ?
- Le runner a-t-il les labels requis ?
- Si vous utilisez ARC, le pod
listenerest-il en cours d'exécution ? - Le runner est-il enregistré au niveau du dépôt, de l'organisation ou de l'entreprise ?
- Si votre dépôt est public, avez-vous activé les dépôts publics pour le runner ?
- Attention, cela signifie que n'importe qui pourrait démarrer un workflow si vous utilisez un déclencheur de pull request.
Pour ARC, rappelez-vous que la valeur de runs-on doit correspondre au nom d'installation du runner scale set.
Impossible de se connecter au démon Docker
Le runner n'a pas accès à Docker.
C'est courant avec les runners auto-hébergés basés sur Kubernetes. Les solutions possibles incluent :
- Configurer Docker-in-Docker.
- Utiliser BuildKit sans Docker.
- Utiliser Kaniko ou Buildah.
- Utiliser un builder distant.
Ne montez pas aveuglément /var/run/docker.sock depuis l'hôte. C'est puissant, mais cela peut donner au job un contrôle proche du niveau de l'hôte.
permission_denied: write_package
Le workflow ne peut pas pousser vers GHCR.
Vérifiez :
- Le job a-t-il la permission
packages: write? - Utilisez-vous
secrets.GITHUB_TOKENcorrectement ? - Le paquet est-il connecté au dépôt ?
- Le paquet a-t-il été créé manuellement avant le workflow ?
- Poussez-vous vers le bon propriétaire et le bon chemin de dépôt ?
ImagePullBackOff
Kubernetes ne peut pas tirer l'image.
Vérifiez :
kubectl -n my-app-prd describe pod <nom-du-pod>
Causes courantes :
- Mauvais nom d'image.
- Mauvais tag.
- Image GHCR privée sans
imagePullSecret. - Le token n'a pas la permission
read:packages. - Limitation de débit du registre ou problème réseau.
Si vous en avez assez des limitations de registre, vous pouvez auto-héberger un registre de conteneurs pour garder vos images plus près de l'endroit où elles sont construites et déployées.
N'oubliez pas l'architecture ARM64 vs AMD64
Pour un Raspberry Pi ou un cluster basé sur ARM, faites attention à l'architecture de l'image. Si GitHub construit une image amd64 et que votre Pi a besoin de arm64, le pod échouera. Docker Buildx peut construire des images multi-architectures :
- name: Build and push multi-arch image
uses: docker/build-push-action@v6
with:
context: .
push: true
platforms: linux/amd64,linux/arm64
tags: ${{ steps.image.outputs.image }}
C'est utile si vous développez sur une architecture et déployez sur une autre.