La distillation de modèles IA : principe, méthodes, avantages et limites
Les grands modèles d'intelligence artificielle (IA) moderne exigent une puissance de calcul et une mémoire massives. Cela les rend couteux et peu pratiques pour les appareils en périphérie (edge devices) ou les applications nécessitant une faible latence.
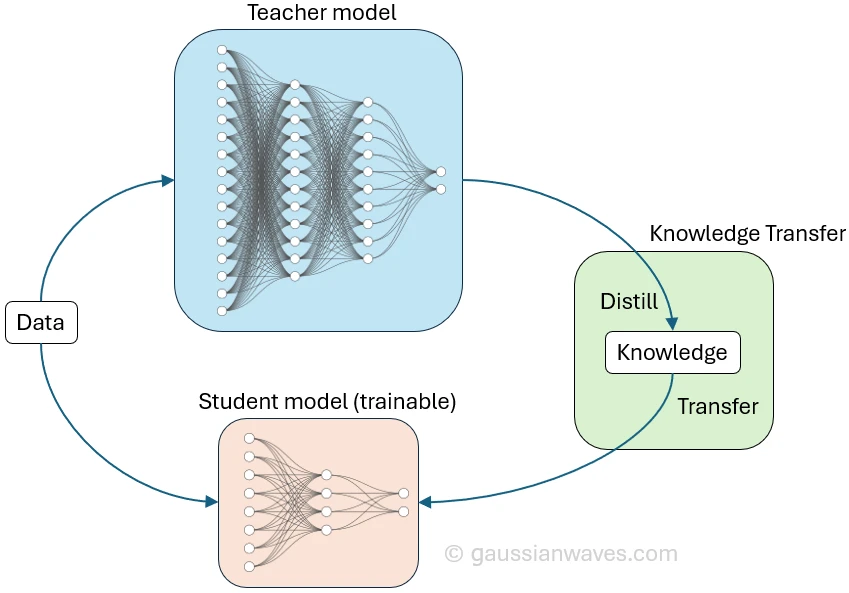
La distillation de modèles (Model Distillation) est le processus qui consiste à compresser les connaissances d'un grand modèle d'IA (aussi appelé le professeur) dans un modèle plus compact et efficace (aussi appelé l'élève). Cela permet d'avoir des modèles plus efficaces tout gardant une grande performance. Laissez-moi vous expliquer.
Pourquoi avons-nous besoin de la distillation de modèles ?
Pourquoi ne pas créer directement des petits modèles? Bien que ce soit possible, la distillation offre certains avantages et a permis de créer des déclinaisons connues comme Llama 3.1 8B (distillé depuis la version 405B) ou encore Ministral (depuis Mistral Large) :
Premièrement, cela donne de meilleurs résultats. Les modèles plus grands sont fondamentalement plus performants, particulièrement à partir de données limitées (source). Un petit modèle a plus de mal à intégrer l'information à partir des données brutes et apprendra mieux à travers le plus grand modèle professeur.
Deuxièmement, si un grand modèle puissant existe déjà, transférer ses connaissances vers un modèle plus petit est jusqu'à deux fois plus rapide et nécessite moins de données d'entraînement comparé à un démarrage de zéro (source).
Comment ça marche la distillation de modèles ?
Une analogie
Imaginez devoir étudier un manuel de 1 000 pages pour un examen. Un expert vous donne un guide de 100 pages avec les résumés, les explications clés et le raisonnement essentiel. C’est beaucoup plus facile à apprendre. Vous n’avez pas toute la profondeur du manuel original, mais vous comprenez assez bien les concepts pour réussir.

La distillation de modèle fonctionne de manière similaire. Le modèle professeur prémâche l'information avant de la montrer à l'élève. Ce faisant, l'élève apprend plus vite même s'il perd certaines subtilités.
Etape 1 : On entraîne le modèle professeur
Le modèle professeur (Teacher Model) est un réseau à haute capacité (comme un grand cerveau) entraîné sur des ensembles de données massifs pour atteindre une précision de premier ordre (voir 1, 2, 3).
Imaginez que nous l'entraînions pour reconnaître des images de chat ou de chien. Des chercheurs créent donc un jeu de données avec des exemples d'images et un label pour chaque.

Le professeur est alors entraîné comme toute IA le serait : on lui donne une image de chat et on s'attend à ce qu'il nous dise si c'est un chien ou un chat. On appelle ça un étiquetage dur (Hard Labeling) : soit 100 % chien ou 100 % chat. S'il se trompe, on le corrige jusqu'à ce qu'il arrive à comprendre la différence.
En pratique, le modèle ne répondra jamais "ceci est 100 % chat". Plutôt, il répond "je suis sûr à 85 % que c'est un chat mais il y a 15 % de chance que ce soit un chien". On appelle ça un étiquetage souple (Soft Labeling). On peut aussi interpréter ça comme "ceci est 85 % un chat et 15 % un chien".
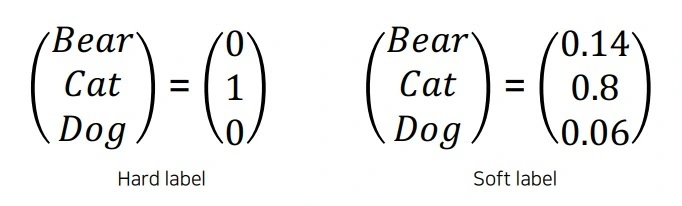
Etape 2 : On entraîne le modèle élève grâce aux étiquettes souples
Le modèle élève (Student Model) est un réseau neuronal plus petit et plus léger. Il n'est pas aussi complexe que le professeur, mais avec la bonne architecture, il est pleinement capable d'apprendre les connaissances distillées.
La distillation fonctionne car on entraîne le modèle élève avec les réponses du professeur qui sont vues comme un ré-étiquetage souple des données. Etonnamment, en utilisant cet étiquetage souple, le modèle élève est plus performant.
En effet, ces étiquettes souples sont incroyablement précieuses car elles révèlent le "processus de réflexion" du modèle professeur et comment il perçoit les relations entre les différentes classes (source). Le modèle élève peut alors exploiter cette information plus riche pour apprendre plus efficacement.
Des implications psycho-philosophiques
Nous humains aimons mettre les choses dans des boîtes très claires. Soit c'est un chien, soit c'est un chat. Cependant, les chats et les chiens sont fort similaires (4 pattes, 2 oreilles...). Au final, ce sont tous les deux des mammifères, donc il y a tout un tas de similarités.
Cela révèle un concept psycho-philosophique profond : notre cerveau a tendance à classer les choses avec des étiquettes dures. La distillation de modèles IA montre pourtant qu’il existe une perte d’information dans cette catégorisation rigide. Comme quoi on en apprend aussi sur nous-mêmes à travers l'IA.
Méthodes de distillation de modèles avancées
Le calibrage de température expliqué
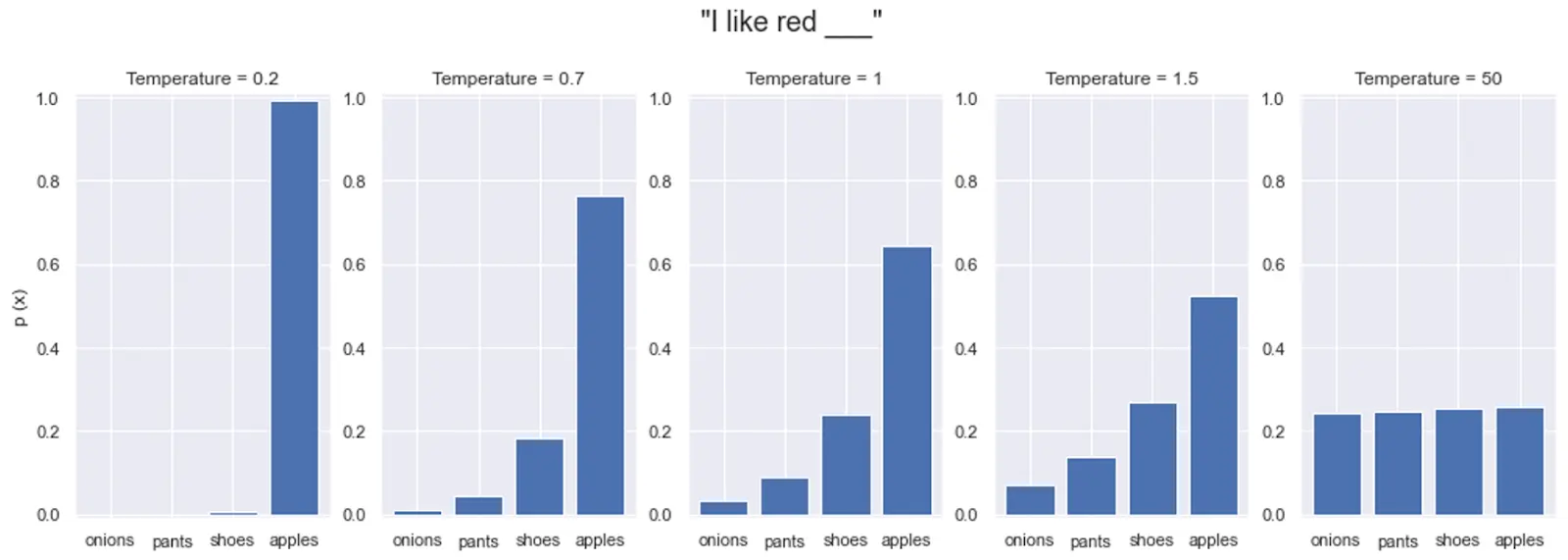
Pour rendre les étiquettes souples encore plus informatives, nous utilisons une technique appelée le Calibrage de température (Temperature Scaling). Lorsqu'un modèle professeur est très confiant, ses étiquettes souples peuvent sembler presque identiques aux étiquettes dures (par ex., 99,9 % Chat, 0,01 % Chien).
En ajustant un paramètre de "température" (en l'augmentant), nous "adoucissons" ou aplatissons les probabilités. Une température plus élevée rend la sortie du modèle moins pointue, atténuant la certitude et révélant les relations cachées entre les classes moins probables. Cela offre à l'élève une courbe d'apprentissage plus douce et plus nuancée.
Distillation de connaissances pour les LLMs
Avec les grands modèles de langage (LLMs - Large Language Models), la distillation de connaissances a évolué pour capturer plus que de simples probabilités de classification :
- Distillation des logits (Logit Distillation) : C'est de la distillation classique. L'élève aligne directement les probabilités de sortie de son vocabulaire (logits) sur les logits du professeur.
- Distillation de réponse/instruction (Response Distillation) : Ici, l'élève apprend à imiter le texte final généré par le professeur pour un prompt spécifique. La distillation vise donc le résultat global et non pas la génération mot par mot.
- Distillation de raisonnement (Reasoning Distillation) : L'élève apprend la logique intermédiaire étape par étape (Chain of Thought - CoT). Par exemple, DeepSeek-R1 a réussi à distiller ses capacités de raisonnement avancées dans des modèles plus petits.
Autres techniques avancées de distillation
Je vous ai présenté l'idée générale de la distillation mais évidemment, il y a beaucoup de variété dans l'implementation de cette idée :
- Auto-distillation (Self-Distillation) : Le modèle s'enseigne à lui-même en s'améliorant itérativement sur ses propres prédictions.
- Distillation récursive (Recursive Distillation) : Un enseignement sur plusieurs générations, où un modèle distillé devient le professeur du modèle suivant. Je suspecte que c'est ainsi qu'OpenAI a produit ses offres GPT-4o, GPT-4o mini et GPT-4o nano : chacun distillé à partir du précédent.
- FitNets : Transfère les représentations latentes/embeddings intermédiaires (ce que le modèle "pense" à mi-chemin) plutôt que seulement la sortie finale (source).
- Réseaux Renaissants (Born-Again Networks) : L'élève possède exactement la même architecture que le professeur. Dans ce cas, on ne compresse pas mais on surpasse parfois les performances du professeur (source).
- Ensemble de Professeurs (Teacher Ensembles) : Utiliser un groupe de professeurs et faire la moyenne de leurs connaissances lors de l'enseignement à l'élève (source).
- Transfert d'attention (Attention Transfer) : En apprenant au modèle élève où "concentrer" son attention (Attention Maps), il apprend à prioriser les mêmes parties des données que le modèle professeur trouve importantes (source).

Les avantages et limites de la distillation de modèles
Avantages
- Taille & Stockage réduits : Les modèles plus petits nécessitent une fraction de l'espace de stockage, leur permettant de s'intégrer sur des appareils en périphérie (edge devices) comme les smartphones.
- Latence plus faible : Moins de calculs signifie une inférence (inference) plus rapide, ce qui est crucial pour les applications en temps réel comme la conduite autonome.
- Efficacité énergétique : Moins de puissance de calcul se traduit par une consommation d'énergie considérablement réduite.
- Meilleures performances : Un élève distillé surpasse généralement un modèle de la même taille exacte entraîné à partir de zéro (from scratch).
Limites
- Écart de capacité (Capacity Gap) : Si l'architecture de l'élève est trop petite ou incompatible, il ne sera pas capable d'absorber la complexité du professeur. Trouver le bon équilibre est crucial.
- Exagération des biais : Un élève peut hériter des biais, des angles morts et des hallucinations du professeur. Il peut parfois aussi les accentuer (source). Si le professeur a des préjugés, l'élève risque de les simplifier et donc de les amplifier.
- Transfert opaque : Il n'est pas toujours clair de savoir exactement quelles connaissances spécifiques l'élève a acquises du professeur (source).
La distillation en pratique
Aujourd'hui, la distillation de modèle est une pratique courante. Les modèles comme GPT-4o mini sont des exemples concrets de distillation. En pratique, ces petits modèles permettent de nombreuses applications :
- Calcul en périphérie & IoT (Internet des Objets) : Thermostats intelligents, objets connectés et smartphones exécutant des IA locales sans latence internet. Cela permet des fonctionnalités telles que la reconnaissance vocale en temps réel.
- Analyse en temps réel : Des caméras de sécurité détectant des objets instantanément en périphérie (on-device), sans envoyer les flux vidéo en continu vers un serveur central.
- IA respectueuse de la confidentialité (Privacy-preserving AI) : Le maintien du traitement des données localement sur l'appareil de l'utilisateur signifie que les informations sensibles n'ont pas besoin de quitter le téléphone.
Vous devriez envisager la distillation de modèles lorsque vous avez déjà accès à un modèle massif et très précis mais que vous avez besoin de déployer une IA dans un environnement contraint (vitesse, coût, mémoire).
Distillation vs Fine-Tuning vs Quantification vs Élagage
La distillation n'est qu'une des nombreuses méthodes permettant de réduire la taille des modèles. Voici un tableau comparatif :
| Technique | Fonctionnement | Cas d'usage principal |
|---|---|---|
| Distillation de modèles | Entraîne un petit élève à imiter un grand professeur. | Compresser les connaissances dans une toute nouvelle architecture plus petite. |
| Fine-Tuning (Affinage) | Met à jour les poids d'un modèle existant sur de nouvelles données. | Adapter un modèle pré-entraîné à une niche ou tâche spécifique. |
| Quantification | Réduit la précision des poids du modèle (par ex., 16 bits -> 4 bits). | Réduire la taille du modèle et l'utilisation de la mémoire sans changer d'architecture. |
| Élagage (Pruning) | Supprime les connexions neuronales redondantes ou inactives. | Accélérer l'inférence en rendant le réseau plus léger. |
La distillation sauvage
La distillation de connaissances soulève d'importantes questions légales et éthiques. Cela dépend fortement des conditions d'utilisation (Terms of Service) du modèle professeur. Distiller un modèle open-source est généralement acceptable. Cependant, utiliser l'API de modèles propriétaires (comme GPT-4 ou Claude d'Anthropic) pour entraîner des concurrents commerciaux viole souvent leurs conditions d'utilisation.
Récemment, l'industrie a vu émerger de vives controverses autour de cette "distillation sauvage". Pour se protéger de cette extraction illicite de connaissances, les grands laboratoires intègrent désormais des mécanismes de Watermarking (tatouages numériques invisibles) et de Data Poisoning (empoisonnement des données) pour défendre leur propriété intellectuelle (source).
Conclusion
La distillation de modèles est devenue une technique essentielle pour rendre l’intelligence artificielle plus légère, plus rapide et plus accessible. Plutôt que de simplement réduire la taille d’un modèle, elle permet de transférer une partie du savoir d’un grand modèle professeur vers un modèle élève plus compact, tout en conservant une bonne partie de ses performances.
Son intérêt est donc très concret : diminuer les coûts, réduire la latence, améliorer l’efficacité énergétique et rendre possible le déploiement de modèles d’IA dans des environnements contraints comme les smartphones, les objets connectés ou les applications en temps réel.
Cependant, la distillation n’est pas magique. Elle dépend fortement de la qualité du modèle professeur, du choix de l’architecture élève et des données utilisées. Elle peut aussi transférer les biais, les erreurs et les limites du modèle original. Comme souvent en IA, compresser un modèle ne signifie pas seulement gagner en efficacité : cela demande aussi de comprendre ce que l’on garde, ce que l’on perd, et ce que l’on risque d’amplifier.
En résumé, la distillation de modèles est l’une des clés pour faire passer l’IA générative d’une technologie puissante mais coûteuse à une technologie réellement déployable, pratique et accessible.



