AI Model Distillation: Principles, Methods, Advantages, and Limitations
Modern artificial intelligence (AI) models require massive computational power and memory. This makes them expensive and impractical for edge devices or applications requiring low latency.
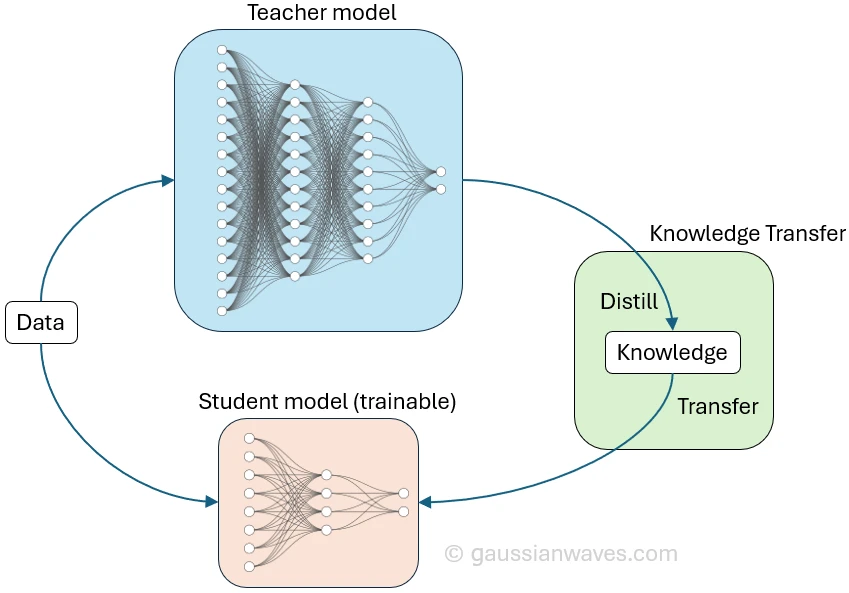
Model Distillation is the process of compressing the knowledge of a large AI model (the teacher) into a more compact and efficient model (the student). This allows for more efficient models while maintaining high performance. Let me explain.
Why do we need model distillation?
Why not simply create small models directly? While possible, distillation offers several advantages and has led to well-known versions like Llama 3.1 8B (distilled from the 405B version) or Ministral (from Mistral Large):
First, it yields better results. Larger models are fundamentally more powerful, especially when learning from limited data (source). A small model struggles more to integrate information from raw data and learns better through the larger teacher model.
Second, if a powerful large model already exists, transferring its knowledge to a smaller model is up to twice as fast and requires less training data compared to starting from scratch (source).
How does model distillation work?
An analogy
Imagine having to study a 1,000-page manual for an exam. An expert gives you a 100-page guide with summaries, key explanations, and essential reasoning. It is much easier to learn. You don't have all the depth of the original manual, but you understand the concepts well enough to succeed.

Model distillation works in a similar way. The teacher model "pre-chews" the information before showing it to the student. In doing so, the student learns faster, even if some subtleties are lost.
Step 1: Train the Teacher Model
The Teacher Model is a high-capacity network (like a large brain) trained on massive datasets to achieve top-tier accuracy (see 1, 2, 3).
Imagine we are training it to recognize images of cats or dogs. Researchers create a dataset with image examples and a label for each.

The teacher is then trained like any AI would be: we give it an image of a cat and expect it to tell us if it's a dog or a cat. This is called Hard Labeling: either 100% dog or 100% cat. If it's wrong, we correct it until it understands the difference.
In practice, the model will never answer "this is 100% cat." Instead, it says "I am 85% sure it's a cat, but there is a 15% chance it's a dog." This is called Soft Labeling. We can also interpret this as "this is 85% cat and 15% dog."
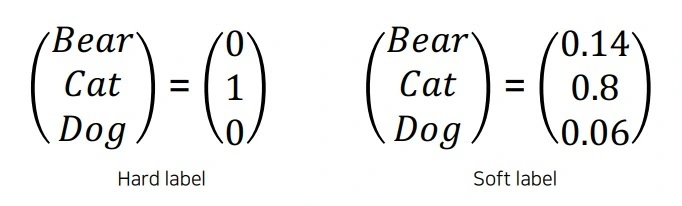
Step 2: Train the Student Model using Soft Labels
The Student Model is a smaller, lighter neural network. It is not as complex as the teacher, but with the right architecture, it is fully capable of learning the distilled knowledge.
Distillation works because we train the student model with the teacher's answers, which are seen as a soft re-labeling of the data. Surprisingly, by using this soft labeling, the student model performs better.
Indeed, these soft labels are incredibly valuable because they reveal the teacher model's "thought process" and how it perceives relationships between different classes (source). The student model can then exploit this richer information to learn more effectively.
Psycho-philosophical implications
We humans love to put things into very clear boxes. It's either a dog or a cat. However, cats and dogs are quite similar (4 legs, 2 ears...). Ultimately, they are both mammals, so there are many similarities.
This reveals a deep psycho-philosophical concept: our brains tend to classify things with hard labels. Yet, AI model distillation shows that there is a loss of information in this rigid categorization. It seems we also learn about ourselves through AI.
Advanced Model Distillation Methods
Temperature Scaling Explained
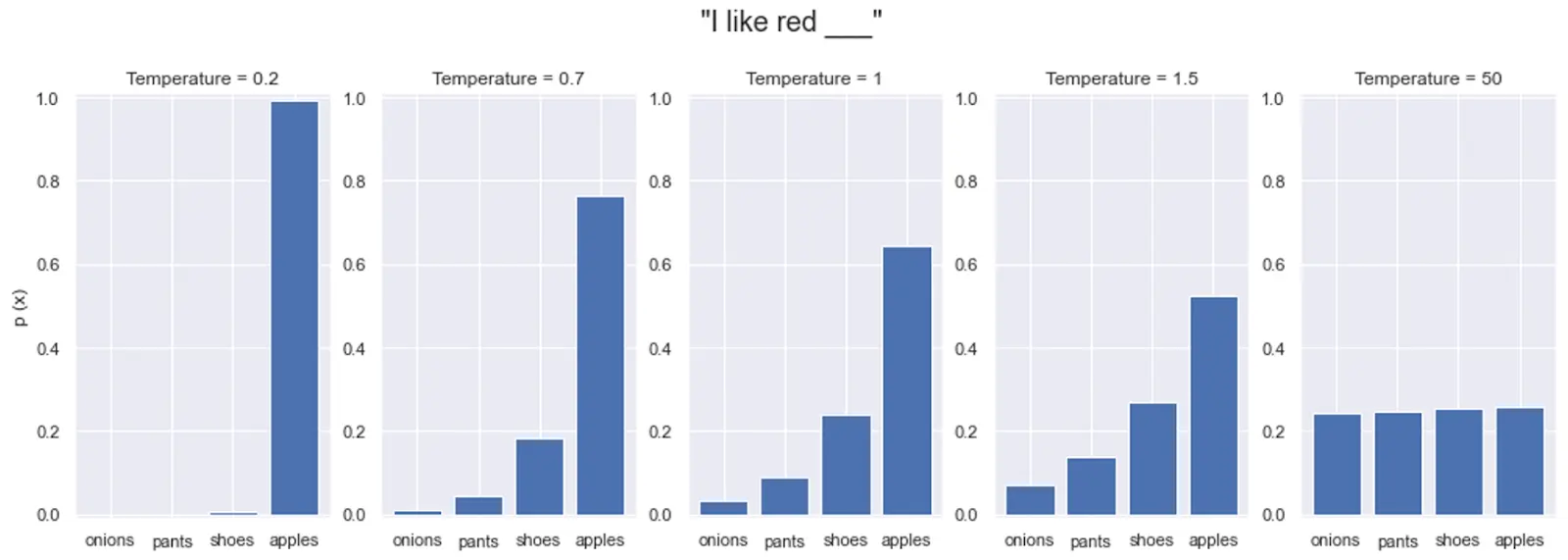
To make soft labels even more informative, we use a technique called Temperature Scaling. When a teacher model is very confident, its soft labels might look almost identical to hard labels (e.g., 99.9% Cat, 0.01% Dog).
By adjusting a "temperature" parameter (increasing it), we "soften" or flatten the probabilities. A higher temperature makes the model's output less sharp, attenuating certainty and revealing hidden relationships between less likely classes. This provides the student with a smoother and more nuanced learning curve.
Knowledge Distillation for LLMs
With Large Language Models (LLMs), knowledge distillation has evolved to capture more than just simple classification probabilities:
- Logit Distillation: This is classic distillation. The student directly aligns its vocabulary's output probabilities (logits) with the teacher's logits.
- Response/Instruction Distillation: Here, the student learns to imitate the final text generated by the teacher for a specific prompt. Distillation thus targets the global result rather than word-by-word generation.
- Reasoning Distillation: The student learns the step-by-step intermediate logic (Chain of Thought - CoT). For example, DeepSeek-R1 successfully distilled its advanced reasoning capabilities into smaller models.
Other Advanced Distillation Techniques
I have presented the general idea of distillation, but obviously, there is great variety in the implementation of this idea:
- Self-Distillation: The model teaches itself by iteratively improving on its own predictions.
- Recursive Distillation: Teaching over several generations, where a distilled model becomes the teacher for the next model. I suspect this is how OpenAI produced its GPT-4o, GPT-4o mini, and GPT-4o nano offerings: each distilled from the previous one.
- FitNets: Transfers intermediate latent representations/embeddings (what the model "thinks" halfway through) rather than just the final output (source).
- Born-Again Networks: The student has exactly the same architecture as the teacher. In this case, there is no compression, but the student sometimes surpasses the teacher's performance (source).
- Teacher Ensembles: Using a group of teachers and averaging their knowledge when teaching the student (source).
- Attention Transfer: By teaching the student model where to "focus" its attention (Attention Maps), it learns to prioritize the same parts of the data that the teacher model finds important (source).

Advantages and Limitations of Model Distillation
Advantages
- Reduced Size & Storage: Smaller models require a fraction of the storage space, allowing them to fit on edge devices like smartphones.
- Lower Latency: Fewer computations mean faster inference, which is crucial for real-time applications like autonomous driving.
- Energy Efficiency: Less computational power translates to significantly reduced energy consumption.
- Better Performance: A distilled student typically outperforms a model of the exact same size trained from scratch.
Limitations
- Capacity Gap: If the student's architecture is too small or incompatible, it will not be able to absorb the teacher's complexity. Finding the right balance is crucial.
- Bias Exaggeration: A student may inherit biases, blind spots, and hallucinations from the teacher. Sometimes it can even accentuate them (source). If the teacher has prejudices, the student risks simplifying and thus amplifying them.
- Opaque Transfer: It is not always clear exactly what specific knowledge the student has acquired from the teacher (source).
Distillation in Practice
Today, model distillation is a common practice. Models like GPT-4o mini are concrete examples of distillation. In practice, these small models enable numerous applications:
- Edge Computing & IoT (Internet of Things): Smart thermostats, connected objects, and smartphones running local AIs without internet latency. This enables features such as real-time voice recognition.
- Real-time Analysis: Security cameras detecting objects instantly on-device, without continuously sending video streams to a central server.
- Privacy-preserving AI: Keeping data processing local on the user's device means sensitive information doesn't need to leave the phone.
You should consider model distillation when you already have access to a massive and highly accurate model but need to deploy AI in a constrained environment (speed, cost, memory).
Distillation vs. Fine-Tuning vs. Quantization vs. Pruning
Distillation is just one of many methods for reducing model size. Here is a comparative table:
| Technique | How it works | Primary use case |
|---|---|---|
| Model Distillation | Trains a small student to imitate a large teacher. | Compressing knowledge into a completely new, smaller architecture. |
| Fine-Tuning | Updates the weights of an existing model on new data. | Adapting a pre-trained model to a specific niche or task. |
| Quantization | Reduces the precision of model weights (e.g., 16-bit -> 4-bit). | Reducing model size and memory usage without changing the architecture. |
| Pruning | Removes redundant or inactive neural connections. | Speeding up inference by making the network lighter. |
Wild Distillation
Knowledge distillation raises important legal and ethical questions. It depends heavily on the teacher model's Terms of Service. Distilling an open-source model is generally acceptable. However, using the API of proprietary models (like OpenAI's GPT-4 or Anthropic's Claude) to train commercial competitors often violates their terms of use.
Recently, the industry has seen sharp controversies emerge around this "wild distillation." To protect against this illicit knowledge extraction, large labs now integrate Watermarking (invisible digital signatures) and Data Poisoning mechanisms to defend their intellectual property (source).
Conclusion
Model distillation has become an essential technique for making artificial intelligence lighter, faster, and more accessible. Rather than simply reducing a model's size, it allows for transferring some of the knowledge from a large teacher model to a more compact student model, while retaining a good portion of its performance.
Its value is very concrete: lowering costs, reducing latency, improving energy efficiency, and enabling the deployment of AI models in constrained environments like smartphones, connected objects, or real-time applications.
However, distillation is not magic. It depends heavily on the quality of the teacher model, the choice of the student architecture, and the data used. It can also transfer the original model's biases, errors, and limitations. As is often the case in AI, compressing a model doesn't just mean gaining efficiency: it also requires understanding what is kept, what is lost, and what risks being amplified.
In summary, model distillation is one of the keys to transforming generative AI from a powerful but expensive technology into one that is truly deployable, practical, and accessible.



